Is there a way to make up for the lack of time the student has but they have the attitude and ability? May 16, 2024. Read blog.
Multiple Chance Testing as a Gateway to Standards-Based Grading, May 6, 2024. Read blog.
Should we get into a tizzy about students meeting deadlines, April 7,2024. Read blog.
Effect of Multiple Chance Testing on Student Performance and Perception, April 6,2024. Read blog.
How do I solve a first order ODE numerically in MATLAB? October 15,2023. Read blog.
Journal paper on use of adaptive learning in flipped classrooms published, August 28, 2023. Read blog.
Asking ChatGPT to look at my student evaluations to give me advice on improving my teaching, May 19, 2023. Read blog.
A VBA function for Cohen’s effect size, May 14,2023. Read blog.
Using PollEveryWhere in University of South Florida, January 18,2023. Read blog.
Balancing the social mobility index and reputation rankings, December 19,2022. Read blog.
Integrating functions given at discrete points via MATLAB, March 6,2022. Read blog.
Quick Start Guide to OpenMCR Program for a Single Key Exam, October 11, 2021. Read blog.
A multiple-choice question response reader, September 29, 2021. Read blog.
Getting last name and first name from full name with a delimited comma, September 11, 2021. Read blog.
A javascript code for Romberg integration, April 14, 2021. Read blog.
Removing YAML from an RMD file through an R script, March 10, 2021. Read blog.
Useful hints for a newbie on Rmarkdown, March 7, 2021. Read blog.
Converting a Word docx file to a draft R Markdown file, February 28, 2021. Read blog.
Canvas quiz times for accommodating students with disabilities, February 7, 2021. Read blog.
A prompt for students to write a discussion post on the most difficult topic in a chapter. January 2, 2021. Read blog.
How do I do that in MATLAB for USF students, December 22, 2020. Read blog.
Gaussian quadrature and weights listed as scrapeable data, October 31, 2020. Read blog.
Multiple Choice Analyzer, September 8, 2020. Read blog.
An Example of Doing Learner Introductions in an Online Class, September 2, 2020. Read blog.
How do I solve an initial value ODE problem in MATLAB? Updated for MATLAB 2020a, July 3, 2020.Read blog.
Using Microsoft Forms as a Personal Response System, June 13, 2020. Read blog.
How do I do that in MATLAB, May 8, 2020. Read blog.
Need help with programming in MATLAB, May 8, 2020. Read blog.
A short sample programming project to exhibit how to submit one, May 7, 2020. Read blog.
COVID19 Regression Model and Other Thoughts, March 28, 2020. Read blog.
How to Make a PDF file, March 26, 2020. Read blog.
How to PUBLISH in MATLAB, March 25, 2020. Read blog.
Ability to break long fprintf statements, March 23, 2020. Read blog.
On Making A Video Lecture on iPad and Uploading to YouTube, March 20, 2020. Read blog.
Why Do We Use Numerical Methods? March 15, 2020. Read blog.
Why Don’t I Allow (Not Ban) Use of Cell Phones in Class – An Open Letter to Students? January 28, 2020. Read blog.
How do I solve simultaneous linear equations given in equation form? Updated Matlab 2018b, January 22, 2020. Read blog.
How do I solve a nonlinear equation that needs to be setup – Updated to MATLAB 2018b, January 22, 2020. Read blog.
Solution to ordinary differential equations posed as definite integral, January 13, 2020. Read blog.
Student participant costs in NSF budgets counts as direct cost, December 4, 2019. Read blog.
Third Edition of Programming Textbook, November 25, 2019.Read blog.
The program to find the determinant of matrix, November 2, 2019. Read blog.
Time it takes to find a determinant, October 20, 2019. Read blog.
Stripping the tags from an HTML file, August 20, 2019. Read blog.
New site for the Numerical Method MOOC, July 29, 2019. Read blog.
Open Education Resource Repository Links, July 10, 2019. Read blog.
Maximizing the cross-section of a gutter, June 12, 2019. Read blog.
Using Watu quizzes and Latex in WordPress, May 18, 2019. Read blog.
Reducing ordinary differential equations to state variable matrix form, May 15, 2019. Read blog.
Matrix Algebra: Eigenvalues and Eigenvectors, March 30, 2019. Read blog.
Matrix Algebra: Adequacy of Solutions, March 12, 2019. Read blog.
Matrix Algebra: Gauss-Seidel Method, March 1, 2019. Read blog.
Synergistic Activities on NSF Proposals, February 27, 2019. Read blog.
Matrix Algebra: LU Decomposition Method, February 19, 2019. Read blog.
Matrix Algebra: Gaussian Elimination Method, February 9, 2019. Read blog.
Matrix Algebra: System of Equations, January 29, 2019. Read blog.
Adaptive learning improves the flipped classroom, January 22, 2019. Read blog.
Matrix Algebra: Unary Operations, January 19, 2019. Read blog.
Matrix Algebra: Vectors, January 8, 2019. Read blog.
Matrix Algebra: Binary Operations, December 25, 2018. Read blog.
Matrix Algebra: Introduction, December 17, 2018. Read blog.
Reporting results from prior NSF support when PIs on a proposal were PIs on a recent grant, November 30, 2018. Read blog.
An FE Math Problem in Analytical Geometry, November 5, 2018. Read blog.
An FE Exam Math Problem in Partial Differential Calculus, October 8, 2018. Read blog.
An FE Exam Math Problem in Ordinary Differential Equations, September 3, 2018. Read blog.
One Two, No Test Review, August 23, 2018. Read blog.
One, two, buckle my shoe, August 22, 2018. Read blog.
Fulbright Specialist Diary: Day 17 thru 18, August 8, 2018. Read blog.
Fulbright Specialist Diary: Day 16, August 7, 2018. Read blog.
Fulbright Specialist Diary: Day 14-15, August 6, 2018. Read blog.
Fulbright Specialist Diary: Day 12-13, August 5, 2018. Read blog.
Fulbright Specialist Diary: Day 11, August 4, 2018. Read blog.
Fulbright Specialist Diary: Day 10, August 3, 2018. Read blog.
Fulbright Specialist Diary: Day 9, August 2, 2018. Read blog.
Fubright Specialist Diary: Day 7 thru Day 8, August 1, 2018. Read blog.
Fulbright Specialist Diary: Day 6, July 31, 2018. Read blog.
Fulbright Specialist Diary: Day 5, July 30, 2018. Read blog.
Fulbright Specialist Diary: Day 4, July 28, 2018. Read blog.
Fulbright Specialist Program Diary: Day 1 to 3, July 27, 2018. Read blog.
An FE Exam Math Problem in Differential Calculus, July 5, 2018. Read blog.
An FE Exam Math Problem in Analytical Geomtery, May 31, 2018. Read blog.
An FE Exam Math Problem in Complex Algebra, May 2, 2018. Read blog.
How much computational time does it take to find the inverse of a square matrix using Gauss Jordan method? Part 1 of 2. April 2, 2018. Read blog.
Euler’s Method Example for FE Exam, March 26, 2018. Read blog.
Computational Time for Forward Elimination Steps of Naive Gaussian Elimination on a Square Matrix, February 21, 2018. Read blog.
Global truncation error in Euler’s method, January 24, 2018. Read blog.
Resources for Numerical Methods, January 8, 2018. Read blog.
Local truncation error is approximately proportional to square of step size in Euler’s method, January 2, 2018. Read blog.
I thought Gaussian quadrature requires that the integral must be transformed to the integral limit of [-1,1]? November 25, 2017. Read blog.
Converting a date to acceptable format in excel, October 1, 2017. Read blog.
Badges added to MOOC courses, August 27, 2017. Read blog.
Covariance between residuals and predictor variable is zero for a linear regression model. July 19, 2017. Read blog.
Sum of the residuals for the linear regression model is zero. July 6, 2017. Read blog.
A MATHCOUNTS problem solution via abstraction, June 26, 2017. Read blog.
Unexpected zeros error in MATLAB in zeros function, June 3, 2017. Read blog.
Using Smart Sparrow as Clickers, May 24, 2017. Read blog.
Getting Started on Smart Sparrow Adaptive Platform, May 13, 2017. Read blog.
Prerequisite Example for Newton Raphson Method, April 18, 2017. Read blog.
Flipped Learning and Active Learning are Not Synonymous, April 6, 2017. Read blog.
Why I do not allow cell phones or regular laptops in class, March 14, 2017. Read blog.
Background Example for Newton Raphson Method, February 23, 2017. Read blog.
Research Grant Offered to Improve Flipped Classroom through Adaptive Learning, December 20, 2016. Read blog.
Deriving trapezoidal rule using undetermined coefficients, November 22, 2016. Read blog.
Implications of diagonally dominant matrices, November 4, 2016. Read blog.
WordPress does not update image, October 21, 2016. Read blog.
Clearing up the confusion about diagonally dominant matrices – Part 4, October 14, 2016. Read blog.
Clearing up the confusion about diagonally dominant matrices – Part 3, October 6, 2016. Read blog.
Clearing up the confusion about diagonally dominant matrices – Part 2, October 1, 2016. Read blog.
Clearing up the confusion about diagonally dominant matrices – Part 1, September 23, 2016. Read blog.
MOOC Released:Introduction to Numerical Methods – Part 2 of 2, September 14, 2016. Read blog.
Unresolved CANVAS LMS bug in algorithmic quizzes, June 17, 2016. Read blog.
A MOOC on Numerical Methods Released, April 5, 2016. Read blog.
Rejecting roots of nonlinear equation for a physical problem? February 12, 2016. Read blog.
End of semester grading VBA module, December 21, 2015. Read blog.
A quadrature formula example, November 9, 2015. Read blog.
Example to show that a polynomial of order n or less that passes through (n+1) data points is unique. November 4, 2015. Read blog.
Why multiply possible form of part of particular solution form by a power of the independent variable when solving an ordinary differential equation, October 5, 2015. Read blog.
Largest number that can be stored in a floating word of 7 bits, September 2, 2015. Read blog.
MOOC on Introduction to Matrix Algebra released, February 7, 2015. Read blog.
A Floating Point Question Revisited, February 6, 2015. Read blog.
Patriots football deflation given as a lesson learned and as an exercise in Numerical Methods, February 1, 2015. Read blog.
2014 in review, December 29, 2014. Read blog.
An example of Gaussian quadrature rule by using two approaches, December 3, 2014. Read blog.
Open course ware for Matrix Algebra Released, November 14, 2014. Read blog.
Friday October 31, 2014, 11:59PM EDT, November 1, 2014 3:59AM GMT – Release Date for an Opencourseware in Introduction to Matrix Algebra, August 5, 2014. Read blog.
Machine epsilon – Question 5 of 5, July 15, 2014. Read blog.
Repeated roots in ordinary differential equation – next independent solution – where does that come from? July 9, 2014. Read blog.
Machine Epsilon – Question 4 of 5, July 1, 2014. Read blog.
Machine epsilon – Question 3 of 5, June 20, 2014. Read blog.
Machine epsilon – Question 2 of 5, June 11, 2014. Read blog.
Machine epsilon – Question 1 of 5, June 4, 2014. Read blog.
A Facebook Page for Numerical Methods, December 29, 2013. Read blog.
Reconciling secant method formulas, October 1, 2013. Read blog.
A Grant to Study Flipped (Inverted) Classrooms, September 5, 2013. Read blog.
Inverse Factorial, August 26, 2013. Read blog.
The Learning Management System Canvas (Instructure) Lacks Key Feature in Quizzes, June 8, 2013. Read blog.
A MOOC on Introduction to Numerical Methods, June 5, 2013. Read blog.
The decimal point display in TI30Xa calculators, May 7, 2013. Read blog.
Misconceptions about diagonal and tridiagonal matrices, March 30, 2013. Read blog.
Making sense of the Big Oh! January 30, 2013. Read blog.
Using Taylor polynomial to approximately solve an ordinary differential equation, January 22, 2013. Read blog.
2012 in review, December 30, 2012. Read blog.
Proving the denominator of the linear regression formula for its constants is greater than zero. October 7, 2012. Read blog.
Prove that the least squares general straight-line model gives the absolute minimum of the sum of the squares of the residuals? September 3, 2012. Read blog.
Effect of Significant Digits: Example 2: Regression Formatting in Excel, August 19, 2012. Read blog.
Effect of Significant Digits: Example 1: Beam Deflection, August 5, 2012. Read blog.
Length of curve, June 28, 2012. Read blog.
Example: How many significant digits are correct in my answer? May 25, 2012. Read blog.
How many significant digits are correct in my answer? May 16, 2012. Read blog.
Do we have to setup all 3n equations for the n quadratic splines for (n+1) data points? March 24, 2012. Read blog.
Checking if a number is non-negative or not? March 4, 2012. Read blog.
Largest integer that can be represented in a n-bit integer word, February 15, 2012. Read blog.
Printer cuts off MATLAB code and text, January 28, 2012. Read blog.
Differentiating a Discrete Function with Equidistant Points, January 19, 2012. Read blog.
2011 in review, December 31, 2011. Read blog.
Saylor Foundation Harnesses Numerical Methods Resources, December 17, 2011. Read blog.
codecademy.com looks promising, November 30, 2011. Read blog.
Audiovisual Lectures for Novice Programmers, November 25, 2011. Read blog.
Livescribe, September 12, 2011. Read blog.
Does the solve command in MATLAB not give you an answer? September 8, 2011. Read blog.
Computational Time to Find Determinant Using Gaussian Elimination, August 21, 2011. Read blog.
Does the solve command in MATLAB not give you an answer? August 7, 2011. Read blog.
Computational Time to Find Determinant Using CoFactor Method, July 21, 2011. Read blog.
A MATLAB program to find quadrature points and weights for Gauss-Legendre Quadrature rule, July 7, 2011. Read blog.
YouTube Videos on Numerical Methods Cross 1-Million Views Mark, June 27, 2011. Read blog.
A Wolfram demo on how much of a floating ball is under water, June 14, 2011. Read blog.
Order of accuracy of central divided difference scheme for first derivative of a function of one variable, June 2, 2011. Read blog.
A Wolfram demo on converting a decimal number to floating point binary representation, May 24, 2011. Read blog.
A Wolfram Demo for Numerical Differentiation, May 10, 2011. Read blog.
Taylor Series in Layman’s terms, April 29, 2011. Read blog.
Computational Time for Forward Substitution, April 14, 2011. Read blog.
Computational Time for Back Substitution, March 30, 2011. Read blog.
Taylor Series Exercise – Method 3, March 11, 2011. Read blog.
Taylor Series Exercise – Method 2, March 2, 2011. Read blog.
Taylor Series Exercise – Method 1, February 17, 2011. Read blog.
Example: Solving a first order ODE by Laplace transforms, February 3, 2011. Read blog.
Classical Solution Technique to Solve a First Order ODE, January 21, 2011. Read blog.
Example: Solving First Order Linear ODE by Integrating Factor, January 7, 2011. Read blog.
2010 in review, January 2, 2011. Read blog.
Reading an excel file in MATLAB, December 14, 2010. Read blog.
Inverse error function using interpolation, October 4, 2010. Read blog.
Using int and solve to find inverse error function in MATLAB, September 1, 2010. Read blog.
Finding the inverse error function, August 24, 2010. Read blog.
Solving a polynomial equation for the longest mast problem? July 4, 2010. Read blog.
A real-life example of having to solve a nonlinear equation numerically? June 10, 2010. Read blog.
Converting large numbers into floating point format by hand, May 25, 2010. Read blog.
Does it make a large difference if we transform data for nonlinear regression models, April 15, 2010. Read blog.
To prove that the regression model corresponds to a minimum of the sum of the square of the residuals, April 8, 2010. Read blog.
A short online quiz for the MATLAB conditional statements, March 9, 2010. Read blog.
A short online quiz on the for-end loops in MATLAB, February 28, 2010. Read blog.
A video tutorial on Simpson’s 1/3 rule, February 23, 2010. Read blog.
A short online quiz on MATLAB basics, January 30, 2010. Read blog.
How do I read data from a textfile in MATLAB? November 29, 2009. Read blog.
MATLAB code for bubble sort, November 8, 2009. Read blog.
Bubble sorting, November 3, 2009. Read blog.
How do I numerically solve an ODE in MATLAB? October 20, 2009. Read blog.
The continue statement in MATLAB, October 16, 2009. Read blog.
The break statement in MATLAB, October 13, 2009. Read blog.
Are software bugs categorised as “that is the way it is”, September 24, 2009. Read blog.
You can watch the numerical methods videos on a mobile device, September 16, 2009. Read blog.
How do I solve simultaneous linear equations given in equation form? August 21, 2009. Read blog.
How do I solve a set of simultaneous linear equations given in matrix form? August 12, 2009. Read blog.
How do I do polynomial regression in MATLAB? August 3, 2009. Read blog.
How do I display the data of an array in MATLAB? July 8, 2009. Read blog.
Poems on Numerical Methods, July 4, 2009. Read blog.
How do I do spline interpolation in MATLAB? June 20, 2009. Read blog.
How do I do polynomial interpolation in MATLAB, June 11, 2009. Read blog.
How do I solve a boundary value ODE in MATLAB? May 25, 2009. Read blog.
How do I solve an initial value ODE in MATLAB? May 14, 2009. Read blog.
How do I solve a nonlinear equation that needs to be setup in MATLAB? April 17, 2009. Read blog.
How do I solve a nonlinear equation in MATLAB? April 11, 2009. Read blog.
How do I integrate a discrete function in MATLAB? April 3, 2009. Read blog.
How do I integrate a continuous function in MATLAB, March 28, 2009. Read blog.
How do I differentiate in MATLAB? March 21, 2009. Read blog.
Numerical Methods YouTube Video Progress, March 14, 2009. Read blog.
MATLAB code for the efficient automatic integrator, March 5, 2009. Read blog.
An efficient formula for an automatic integrator based on trapezoidal rule, February 28, 2009. Read blog.
Why keep doubling the segments for an automatic integrator based on Trapezoidal rule? February 23, 2009. Read blog.
A problem using central divided difference error order, February 9, 2009. Read blog.
Audiovisual Lectures on Numerical Methods, January 27, 2009. Read blog.
Proper modeling needs to precede numerical solutions, January 15, 2009. Read blog.
Numerical Methods Book Printed, January 8, 2009. Read blog.
Is a square matrix strictly diagonally dominant? November 29, 2008. Read blog.
Skipping numbers in picking the lotto numbers, November 21, 2008. Read blog.
Is a square matrix diagonal or not? November 16, 2008. Read blog.
Picking lotto numbers, November 10, 2008. Read blog.
Comparing two series to calculate pi, October 30, 2008. Read blog.
An automatic integrator using Trapezoidal rule, October 19, 2008. Read blog.
Another improper integral solved using trapezoidal rule, October 8, 2008. Read blog.
The BMI (Body Mass Index) Program, September 28, 2008 .Read blog.
Experimental data for the length of curve experiment, September 21, 2008. Read blog.
A better way to show conversion of decimal fractional number to binary, September 14, 2008. Read blog.
Finding height of atmosphere using nonlinear regression, September 6, 2008. Read blog.
A better way to show decimal to binary conversion, August 30, 2008. Read blog.
Accuracy of Taylor series, August 23, 2008. Read blog.
Taylor series example, August 19, 2008. Read blog.
Taylor Series Revisited, August 11, 2008. Read blog.
Runge-Kutta 2nd order equations derived, August 7, 2008. Read blog.
A Matlab program for comparing Runge-Kutta methods, August 4, 2008. Read blog.
Example to show how numerical ODE solutions can be used to find integrals, July 31, 2008. Read blog.
Comparing Runge-Kutta 2nd order methods, July 28, 2008. Read blog.
Can I use numerical solution of ODE techniques to do numerical integration? July 25, 2008. Read blog.
Time of death – a classic ODE problem, July 21, 2008. Read blog.
Is it just a coincidence – true error in multiple segment Trapezoidal rule gets approximately quartered as the number of segments is doubled? July 18, 2008. Read blog.
Can I use Trapezoidal rule to calculate an improper integral? July 16, 2008. Read blog.
A metric for measuring wildness of a college football season, July 14, 2008. Read blog.
Experiment for spline interpolation and integration, July 11, 2008. Read blog.
Abuses of regression, July 9, 2008. Read blog.
How do you know that the least squares regression line is unique and corresponds to a minimum, July 7, 2008. Read blog.
Finding the optimum polynomial order to use for regression, July 5, 2008. Read blog.
Data for aluminum cylinder in iced water experiment, July 3, 2008. Read blog.
In regression, when is coefficient of determination zero, July 1, 2008. Read blog.
Length of a curve experiment, June 29, 2008. Read blog.
A legend used in the movie “The Happening”, June 27, 2008. Read blog.
Shortest path for a robot, June 25, 2008. Read blog.
Do quadratic splines really use all the data points? June 23, 2008. Read blog.
Extrapolation is inexact and may be dangerous, June 20, 2008. Read blog.
Finding the length of curve using MATLAB, June 18, 2008. Read blog.
A simple MATLAB program to show that High order interpolation is a bad idea, June 16, 2008. Read blog.
High order interpolation is a bad idea? June 14, 2008. Read blog.
If a polynomial of order n or less passes thru (n+1) points, it is unique! June 10, 2008. Read blog.
So what does this mean that the computational time is proportional to some power of n in Gaussian Elimination method? June 9, 2008. Read blog.
An experiment to illustrate numerical differentiation, integration, regression and ODEs, June 7, 2008. Read blog.
Rusty on Matrix Algebra, June 5, 2008. Read blog.
LU Decomposition takes more computational time than Gaussian Elimination! What gives? June 4, 2008. Read blog.
Round off errors and the Patriot missile, June 2, 2008. Read blog.
Myth: Error caused by chopping a number is called truncation error, May 27, 2008. Read blog.
Undergraduate Numerical Methods for Engineering, May 26, 2008. Read blog.

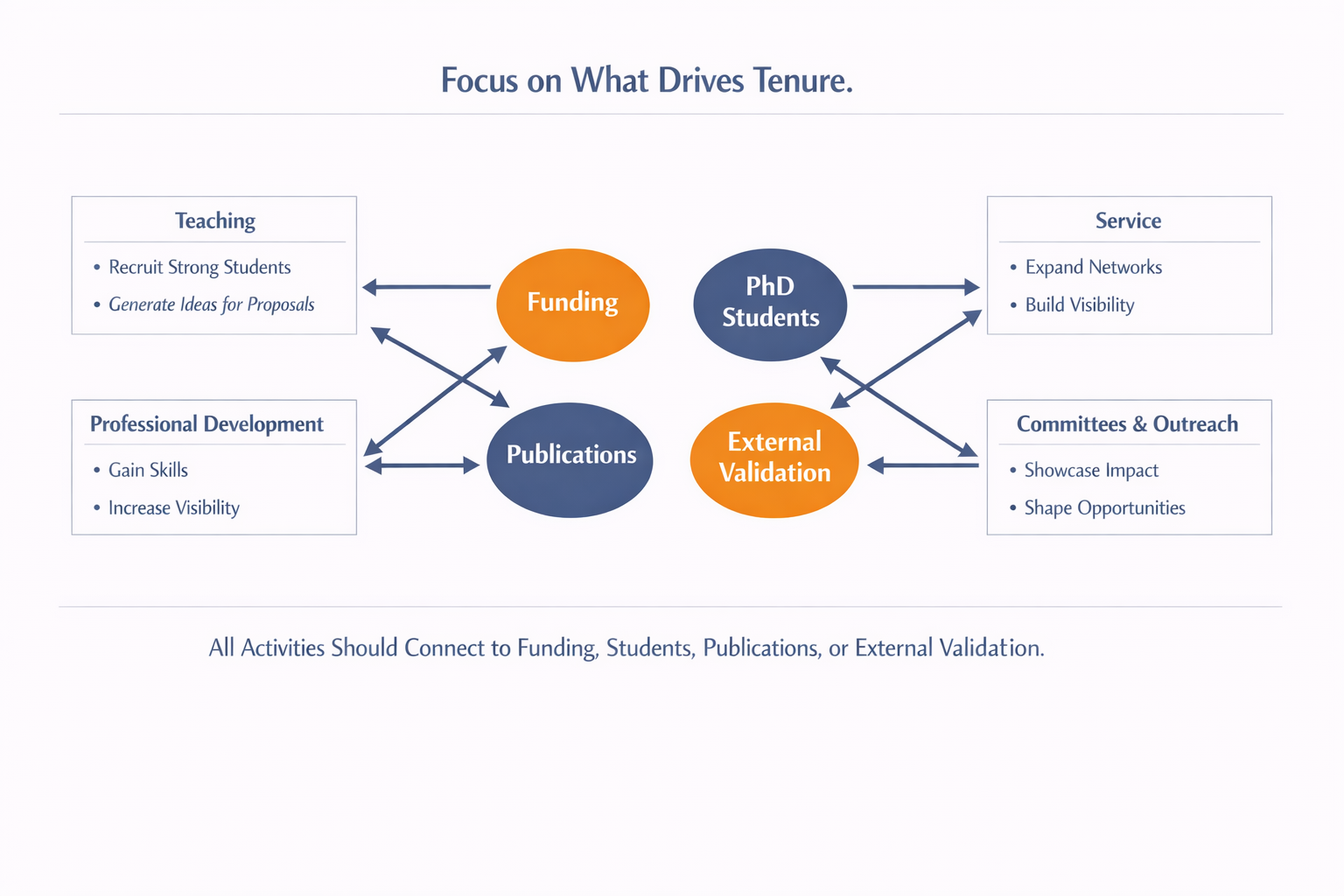
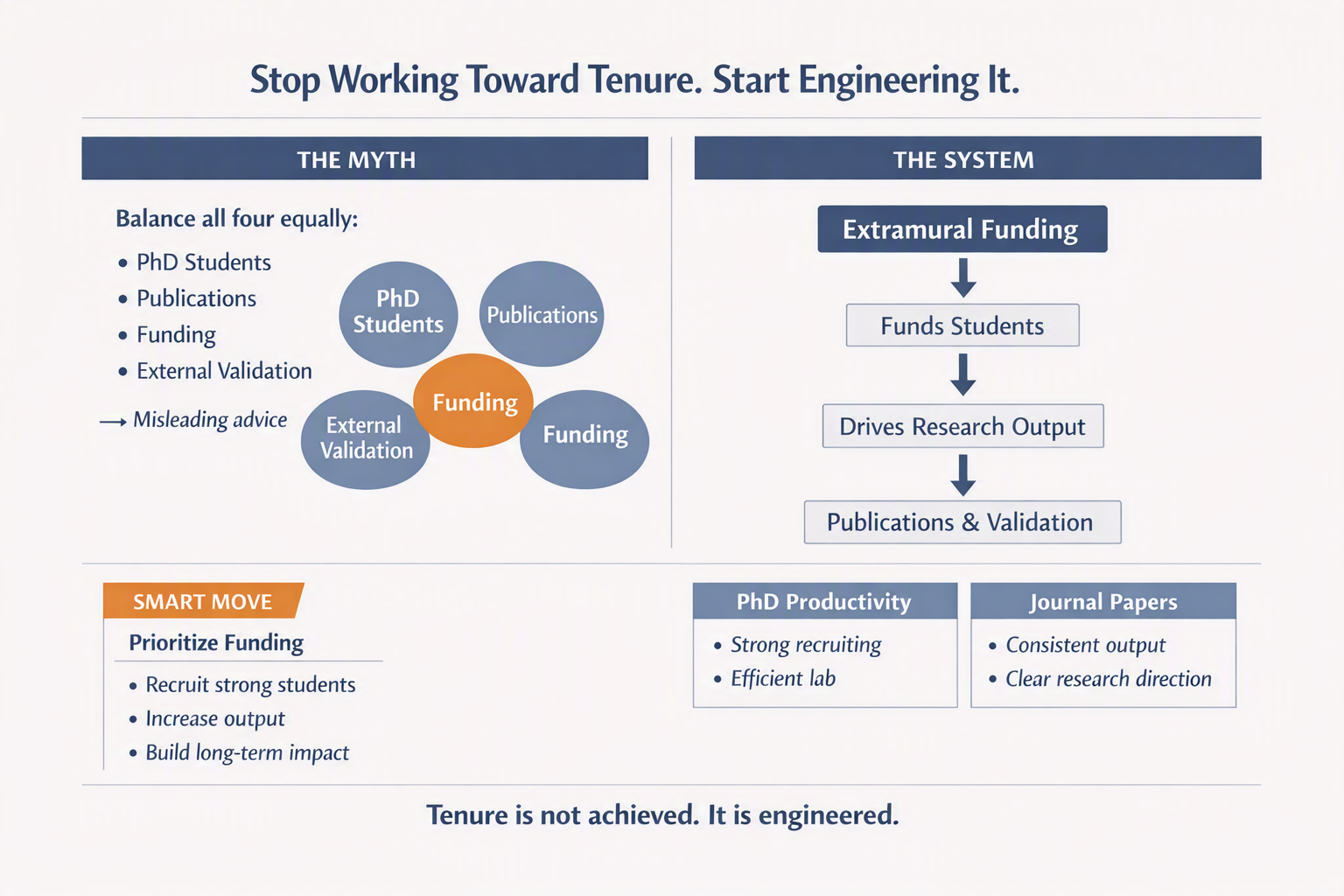 Funding is not just one of the four. It is the driver of the system. Without it, even strong ideas struggle to translate into sustained research. Graduate students do not appear out of interest alone. They follow resources, continuity, and the promise of meaningful work.
Funding is not just one of the four. It is the driver of the system. Without it, even strong ideas struggle to translate into sustained research. Graduate students do not appear out of interest alone. They follow resources, continuity, and the promise of meaningful work.