Many a times, you may not have the privilege or knowledge of the physics of the problem to dictate the type of regression model. You may want to fit the data to a polynomial. But then how do you choose what order of polynomial to use.
Do you choose based on the polynomial order for which the sum of the squares of the residuals, Sr is a minimum? If that were the case, we can always get Sr=0 if the polynomial order chosen is one less than the number of data points. In fact, it would be an exact match.
So what do we do? We choose the degree of polynomial for which the variance as computed by
Sr(m)/(n-m-1)
is a minimum or when there is no significant decrease in its value as the degree of polynomial is increased. In the above formula,
Sr(m) = sum of the square of the residuals for the mth order polynomial
n= number of data points
m=order of polynomial (so m+1 is the number of constants of the model)
Let’s look at an example where the coefficient of thermal expansion is given for a typical steel as a function of temperature. We want to relate the two using polynomial regression.
|
Temperature |
Instantaneous Thermal Expansion |
|
oF |
1E-06 in/(in oF) |
|
80 |
6.47 |
|
40 |
6.24 |
|
0 |
6.00 |
|
-40 |
5.72 |
|
-80 |
5.43 |
|
-120 |
5.09 |
|
-160 |
4.72 |
|
-200 |
4.30 |
|
-240 |
3.83 |
|
-280 |
3.33 |
|
-320 |
2.76 |
If a first order polynomial is chosen, we get
$latex alpha=0.009147T+5.999$, with Sr=0.3138.
If a second order polynomial is chosen, we get
$latex alpha=-0.00001189T^2+0.006292T+6.015$ with Sr=0.003047.
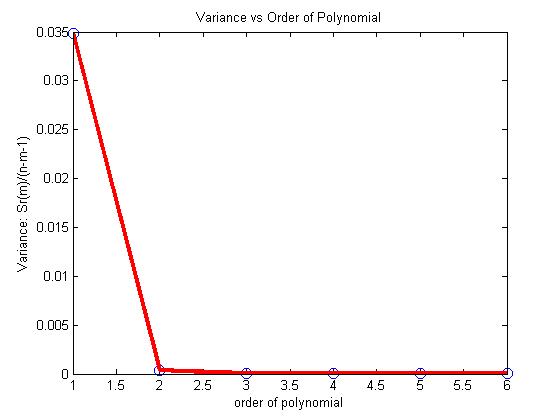
Below is the table for the order of polynomial, the Sr value and the variance value, Sr(m)/(n-m-1)
|
Order of polynomial, m |
Sr(m) |
Sr(m)/(n-m-1) |
|
1 |
0.3138 |
0.03486 |
|
2 |
0.003047 |
0.0003808 |
|
3 |
0.0001916 |
0.000027371 |
|
4 |
0.0001566 |
0.0000261 |
|
5 |
0.0001541 |
0.00003082 |
|
6 |
0.0001300 |
0.000325 |
So what order of polynomial would you choose?
From the above table, and the figure below, it looks like the second or third order polynomial would be a good choice as very little change is taking place in the value of the variance after m=2.
This post is brought to you by Holistic Numerical Methods: Numerical Methods for the STEM undergraduate at http://nm.mathforcollege.com
Subscribe to the feed to stay updated and let the information follow you.