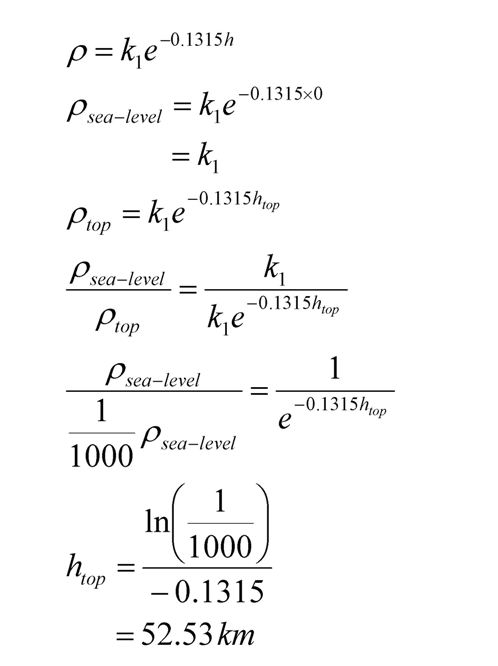
In 1998, the federal government developed the body mass index (BMI) to determine ideal weights. Body mass index is calculated as 703 times the weight in pounds divided by the square of the height in inches, the obtained number is then rounded to the nearest whole number (Hint: 23.5 will be rounded to 24; 23.1 will be rounded to 23; 23.52 will be rounded to 24)
BMI Categories:
BMI <19 (underweight)
19≤BMI≤25 (healthy)
25<BMI≤30 (overweight)
BMI is >30 (obese)
Here is a MATLAB program that calculates the BMI of a person, classifies him/her in the BMI category, and then suggests a healthy weight.
It is better to download the program as single quotes in the pasted version do not translate correctly when pasted into a mfile editor of MATLAB. See the html version for clarity and sample output.
% So you want my phone number and my BMI? How shallow can you get?
% Worksheet : Finding the BMI of a person, classifying the BMI and
% suggesting a healthy weight
% Language : Matlab 2007a
% Authors : Autar Kaw
% Last Revised : September 27, 2008
% Abstract: Finding the body mass index of a person, classifying their health
% and recommending a target weight.
%
% In 1998, the federal government developed the body mass index (BMI)
% to determine ideal weights. Body mass index is calculated as
% 703 times the weight in pounds divided by the square of the height in inches,
% the obtained number is then rounded to the nearest whole number
% (23.5 will be rounded to 24; 23.1 will be rounded to 23; 23.52 will be rounded to 24).
%
% Write a MATLAB program to do the following:
%
% Assign a value to weight in lbs, and height in inches and
% then calculate BMI as a rounded integer.
% Output a variable called health_id as
% 0 if the person’s BMI <19 (underweight)
% 1 if the person’s BMI is 19≤BMI≤25 (healthy)
% 2 if the person’s BMI is 25<BMI≤30 (overweight)
% 3 if the person’s BMI is >30 (obese)
% Output also a variable hw for healthy weight in rounded integer lbs for all the conditions.
% Use fprintf command with explanation for the inputs and outputs
clc
clear all
% INPUTS
% Weight in lbs
weight=180;
% Height in inches
height=69;
%REST OF THE PROGRAM
bmi=weight/height^2*703.0;
bmi=round(bmi);
% Assigning the proper health_id and finding the suggested healthy weight
% health_id= BMI category
% hw = healthy weight
% You can use 4 separate if-end statements or switch case statement also.
if (bmi<19)
health_id=0;
hw=19*height^2/703;
elseif (bmi>=19 & bmi<=25);
health_id=1;
elseif (bmi>25 & bmi<=30);
health_id=2;
hw=25*height^2/703;
else
health_id=3;
hw=25*height^2/703;
end
hw=round(hw);
% Printing the outputs
disp(‘The BMI MATLAB program’)
disp(‘Author: Autar K Kaw’)
disp(‘http://nm.mathforcollege.com’)
disp(‘September 28, 2008’)
disp(‘ ‘)
fprintf(‘\nWeight of person =%6.0f lbs’,weight)
fprintf(‘\nHeight of person =%6.0f inches’,height)
fprintf(‘\nYour BMI is =%g ‘,bmi)
if health_id==0
fprintf(‘\nYou are underweight. \nYour target weight is =%6.0f lbs’,hw)
elseif health_id==1
fprintf(‘\nYou are a healthy weight. \nYour target weight is =%6.0f lbs’,hw)
elseif health_id==2
fprintf(‘\nYou are overweight. \nYour target weight is =%6.0f lbs’,hw)
elseif health_id==3
fprintf(‘\nYou are obese. \nYour target weight is =%6.0f lbs’,hw)
end
________________________________________________________________________________________________
This post is brought to you by Holistic Numerical Methods: Numerical Methods for the STEM undergraduate at http://nm.mathforcollege.com.
An abridged (for low cost) book on Numerical Methods with Applications will be in print (includes problem sets, TOC, index) on December 10, 2008 and available at lulu storefront.
Subscribe to the blog via a reader or email to stay updated with this blog. Let the information follow you.