In a previous post, we compared the results from various 2nd order Runge-Kutta methods to solve a first order ordinary differential equation. In this post, I am posting the matlab program. It is better to download the program as single quotes in the pasted version do not translate properly when pasted into a mfile editor of MATLAB or see the html version for clarity and sample output .
Do your own testing on a different ODE, a different value of step size, a different initial condition, etc. See the inputs section below that is colored in bold brick.
% Simulation : Comparing the Runge Kutta 2nd order method of
% solving ODEs
% Language : Matlab 2007a
% Authors : Autar Kaw
% Last Revised : July 12, 2008
% Abstract: This program compares results from the
% exact solution to 2nd order Runge-Kutta methods
% of Heun’s method, Ralston’s method, Improved Polygon
% method, and directly using the three terms of Taylor series
clc
clear all
clc
clf
disp(‘This program compares results from the’)
disp(‘exact solution to 2nd order Runge-Kutta methods’)
disp(‘of Heuns method, Ralstons method, Improved Polygon’)
disp(‘ method, and directly using the three terms of Taylor series’)
%INPUTS. If you want to experiment these are only things
% you should and can change. Be sure that the ode has an exact
% solution
% Enter the rhs of the ode of form dy/dx=f(x,y)
fcnstr=’sin(5*x)-0.4*y’ ;
% Initial value of x
x0=0;
% Initial value of y
y0=5;
% Final value of y
xf=5.5;
% number of steps to go from x0 to xf.
% This determines step size h=(xf-x0)/n
n=10;
%REST OF PROGRAM
%Converting the input function to that can be used
f=inline(fcnstr) ;
% EXACT SOLUTION
syms x
eqn=[‘Dy=’ fcnstr]
% exact solution of the ode
exact_solution=dsolve(eqn,’y(0)=5′,’x’)
% geting points for plotting the exact solution
xx=x0:(xf-x0)/100:xf;
yy=subs(exact_solution,x,xx);
yexact=subs(exact_solution,x,xf);
plot(xx,yy,’.’)
hold on
% RUNGE-KUTTA METHODS
h=(xf-x0)/n;
% Heun’s method
a1=0.5;
a2=0.5;
p1=1;
q11=1;
xr=zeros(1,n+1);
yr=zeros(1,n+1);
%Initial values of x and y
xr(1)=x0;
yr(1)=y0;
for i=1:1:n
k1=f(xr(i),yr(i));
k2=f(xr(i)+p1*h,yr(i)+q11*k1*h);
yr(i+1)=yr(i)+(a1*k1+a2*k2)*h;
xr(i+1)=xr(i)+h;
end
%Value of y at x=xf
y_heun=yr(n+1);
% Absolute relative true error for value using Heun’s Method
et_heun=abs((y_heun-yexact)/yexact)*100;
hold on
xlabel(‘x’)
ylabel(‘y’)
title_name=[‘Comparing exact and Runge-Kutta methods with h=’ num2str(h)] ;
title(title_name)
plot(xr,yr, ‘color’,’magenta’,’LineWidth’,2)
% Midpoint Method (also called Improved Polygon Method)
a1=0;
a2=1;
p1=1/2;
q11=1/2;
%Initial values of x and y
xr(1)=x0;
yr(1)=y0;
for i=1:1:n
k1=f(xr(i),yr(i));
k2=f(xr(i)+p1*h,yr(i)+q11*k1*h);
yr(i+1)=yr(i)+(a1*k1+a2*k2)*h;
xr(i+1)=xr(i)+h;
end
%Value of y at x=xf
y_improved=yr(n+1);
% Absolute relative true error for value using Improved Polygon Method
et_improved=abs((y_improved-yexact)/yexact)*100;
hold on
plot(xr,yr,’color’,’red’,’LineWidth’,2)
% Ralston’s method
a1=1/3;
a2=2/3;
p1=3/4;
q11=3/4;
xr(1)=x0;
yr(1)=y0;
for i=1:1:n
k1=f(xr(i),yr(i));
k2=f(xr(i)+p1*h,yr(i)+q11*k1*h);
yr(i+1)=yr(i)+(a1*k1+a2*k2)*h;
xr(i+1)=xr(i)+h;
end
%Value of y at x=xf
y_ralston=yr(n+1);
% Absolute relative true error for value using Ralston’s Method
et_ralston=abs((y_ralston-yexact)/yexact)*100;
hold on
plot(xr,yr,’color’,’green’,’LineWidth’,2)
% Using first three terms of the Taylor series
syms x y;
fs=char(fcnstr);
% fsp=calculating f'(x,y) using chain rule
fsp=diff(fs,x)+diff(fs,y)*fs;
%Initial values of x and y
xr(1)=x0;
yr(1)=y0;
for i=1:1:n
k1=subs(fs,{x,y},{xr(i),yr(i)});
kk1=subs(fsp,{x,y},{xr(i),yr(i)});
yr(i+1)=yr(i)+k1*h+1/2*kk1*h^2;
xr(i+1)=xr(i)+h;
end
%Value of y at x=xf
y_taylor=yr(n+1);
% Absolute relative true error for value using Taylor series
et_taylor=abs((y_taylor-yexact)/yexact)*100;
hold on
plot(xr,yr,’color’,’black’,’LineWidth’,2)
hold off
legend(‘exact’,’heun’,’midpoint’,’ralston’,’taylor’,1)
% THE OUTPUT
fprintf(‘\nAt x = %g ‘,xf)
disp(‘ ‘)
disp(‘_________________________________________________________________’)
disp(‘Method Value Absolute Relative True Error’)
disp(‘_________________________________________________________________’)
fprintf(‘\nExact Solution %g’,yexact)
fprintf(‘\nHeuns Method %g %g ‘,y_heun,et_heun)
fprintf(‘\nImproved method %g %g ‘,y_improved,et_improved)
fprintf(‘\nRalston method %g %g ‘,y_ralston,et_ralston)
fprintf(‘\nTaylor method %g %g ‘,y_taylor,et_taylor)
disp( ‘ ‘)
________________________________________________________________________________________________
This post is brought to you by Holistic Numerical Methods: Numerical Methods for the STEM undergraduate at http://nm.mathforcollege.com
Subscribe to the blog via a reader or email to stay updated with this blog. Let the information follow you.





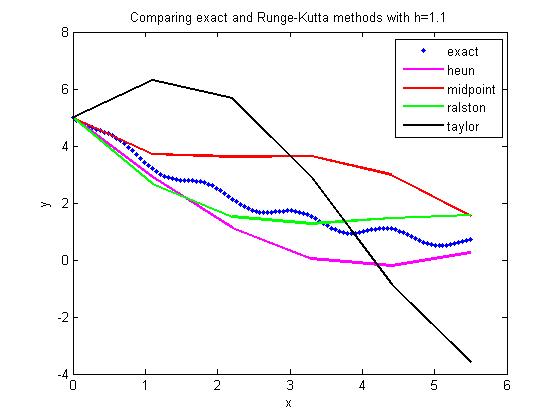
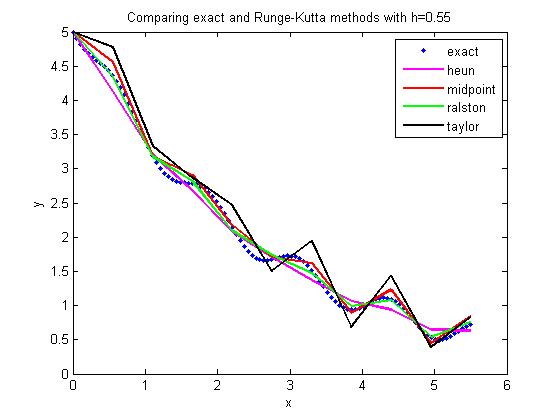



 Exercises assigned to the students:
Exercises assigned to the students: